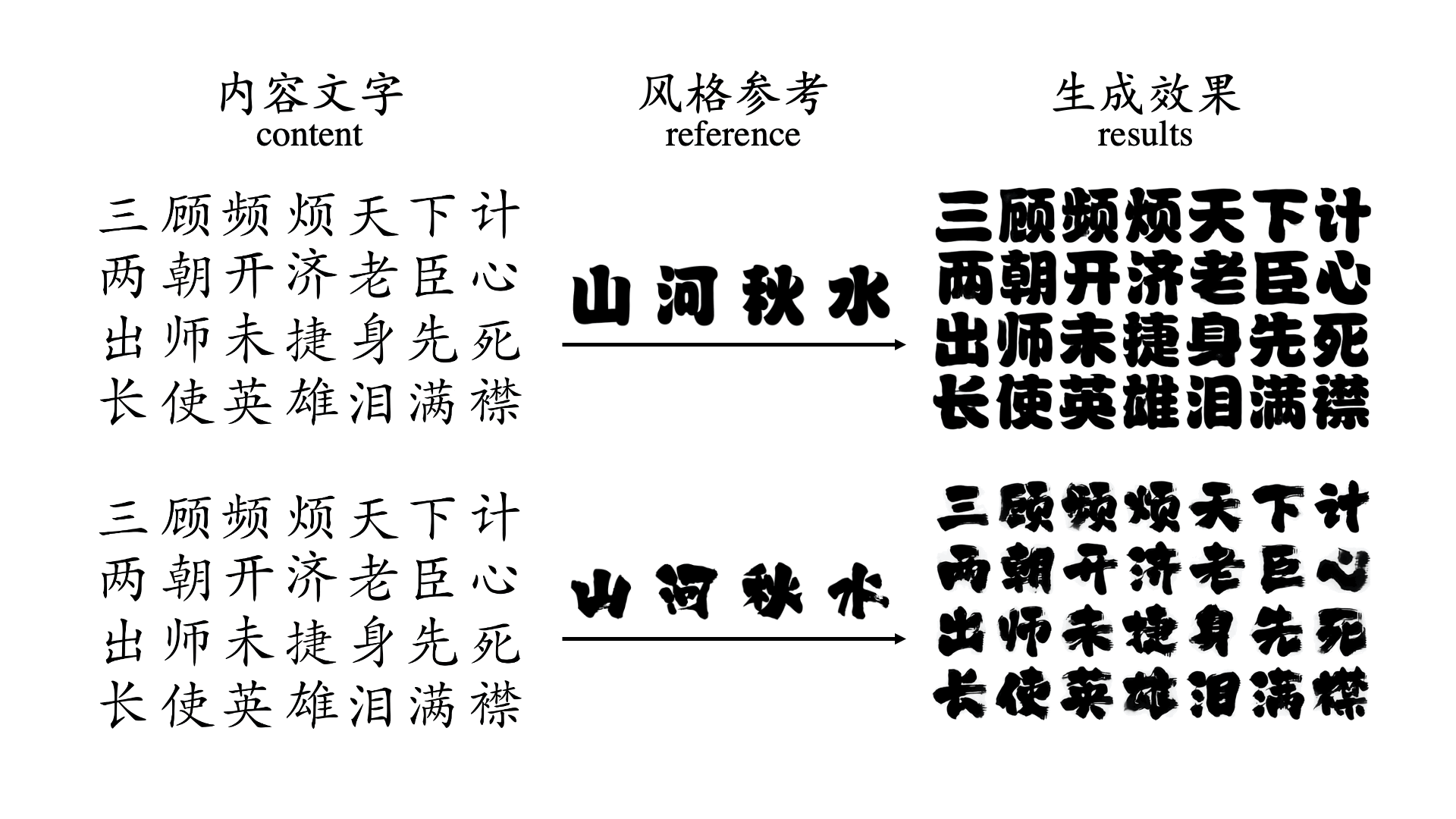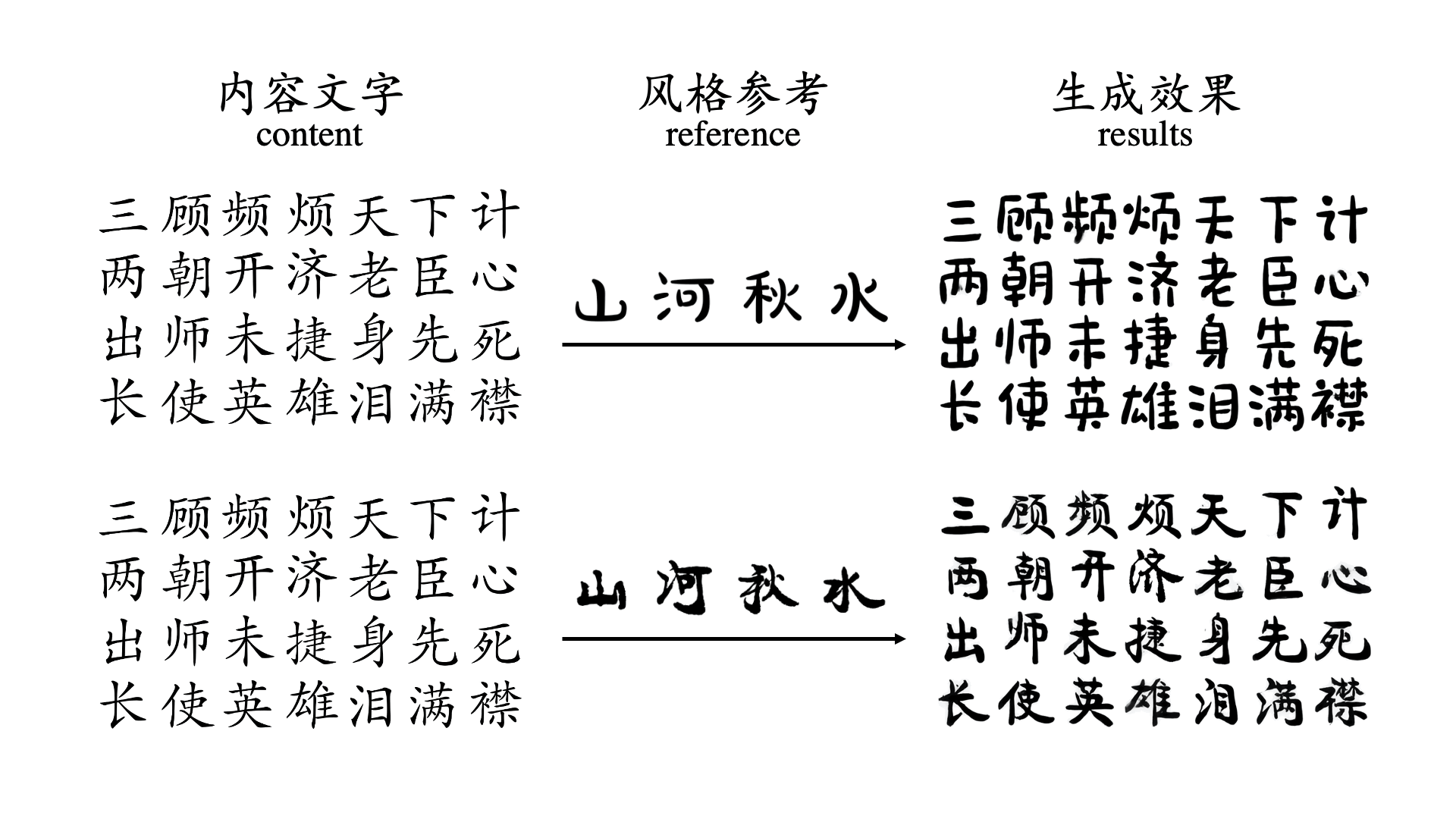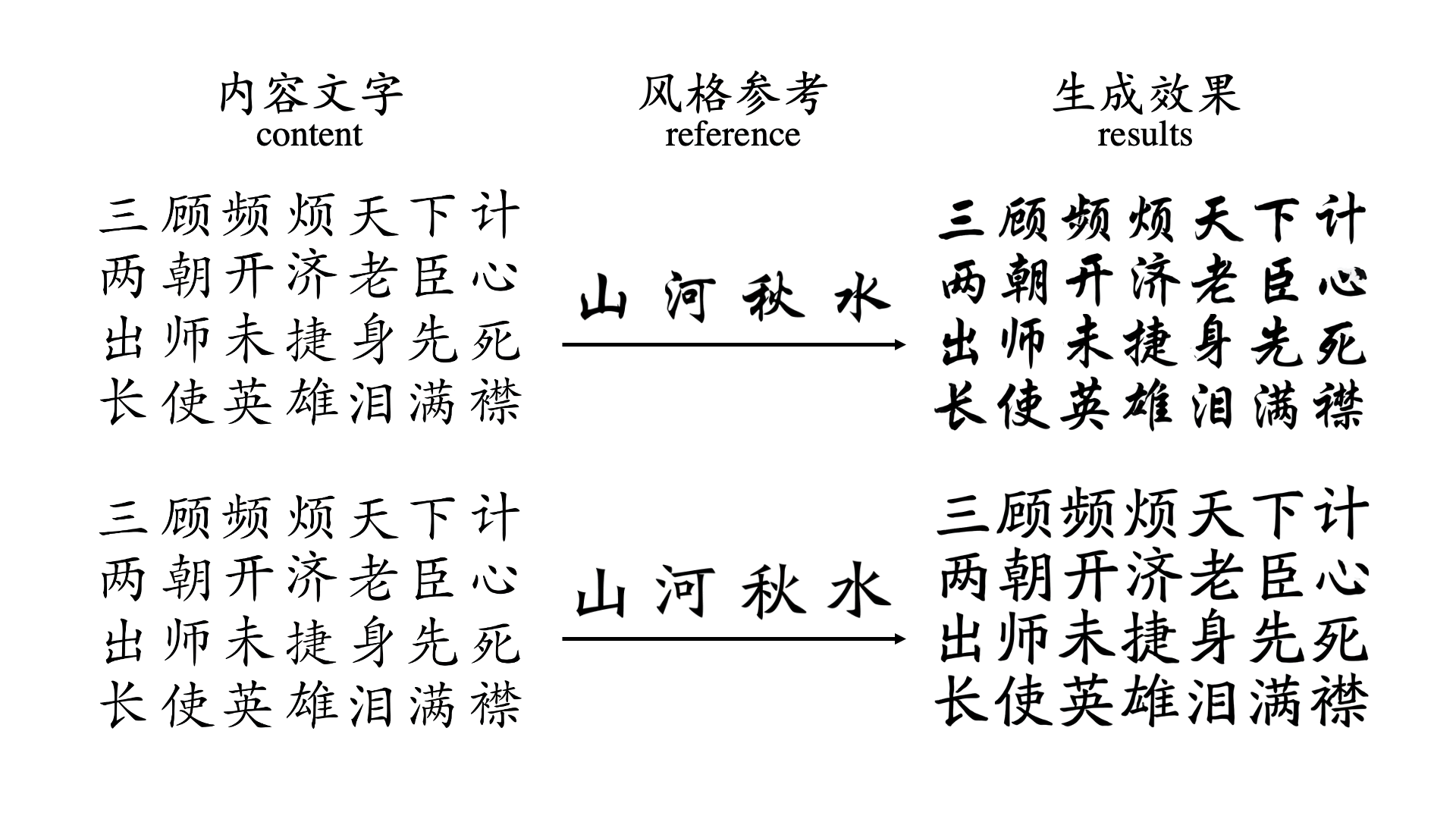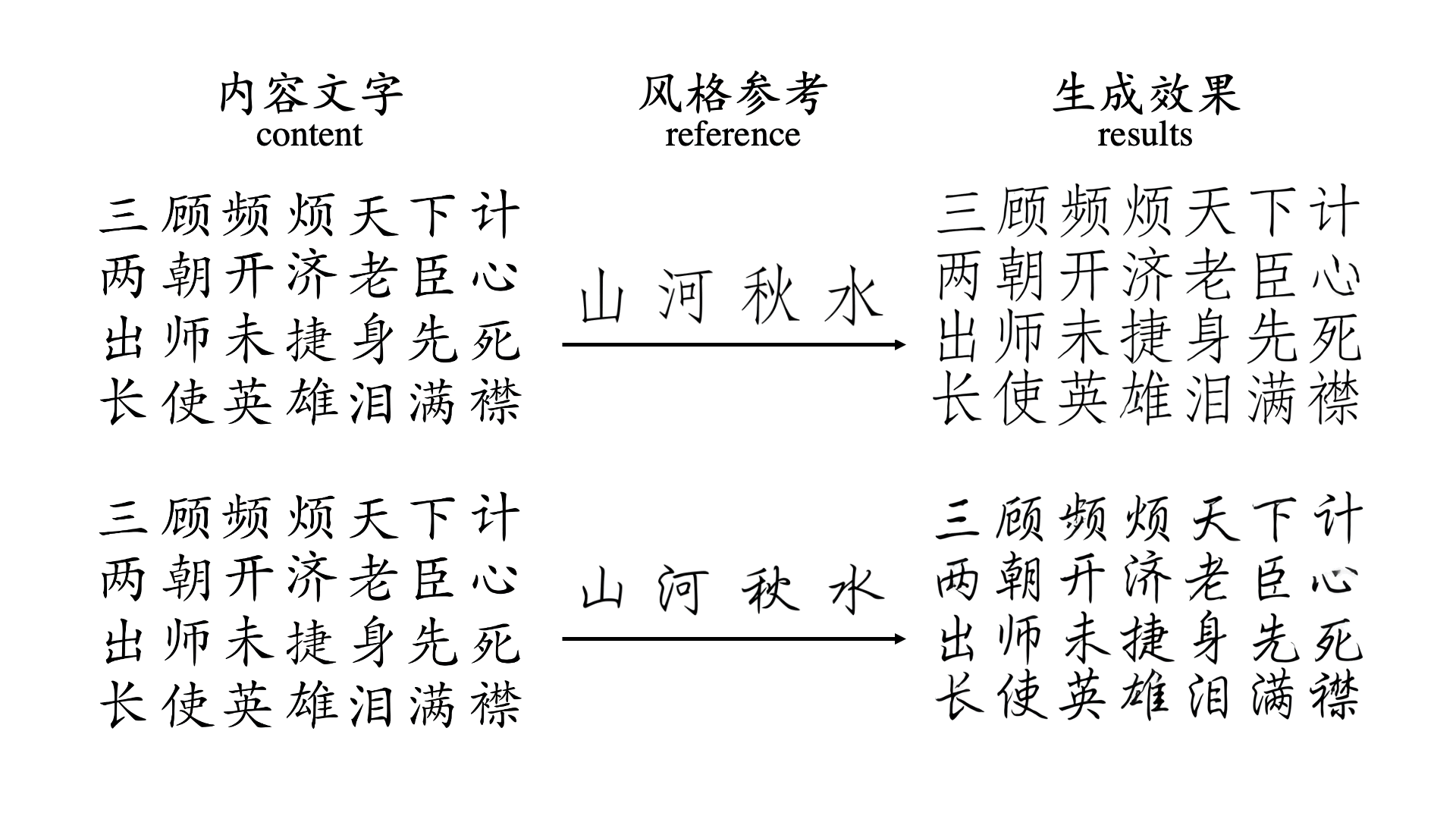
A complete Chinese font includes tens of thousands of Chinese characters, hundreds of different Chinese character components and completely different arrangement and combination methods.
This makes designing a set of Chinese fonts extremely costly in terms of manpower, time and money.
However, because Chinese character fonts have strict requirements on the number, position and frame structure of strokes, general image translation models do not have a deep enough understanding of Chinese characters,
and the frame structure of fonts is also a type of style information, which leads to the generation of most Chinese characters.
The effect is not satisfactory. For some more difficult tasks, such as calligraphy font repair or when there are only a very small number of reference characters, the success rate of previous font generation methods is low.
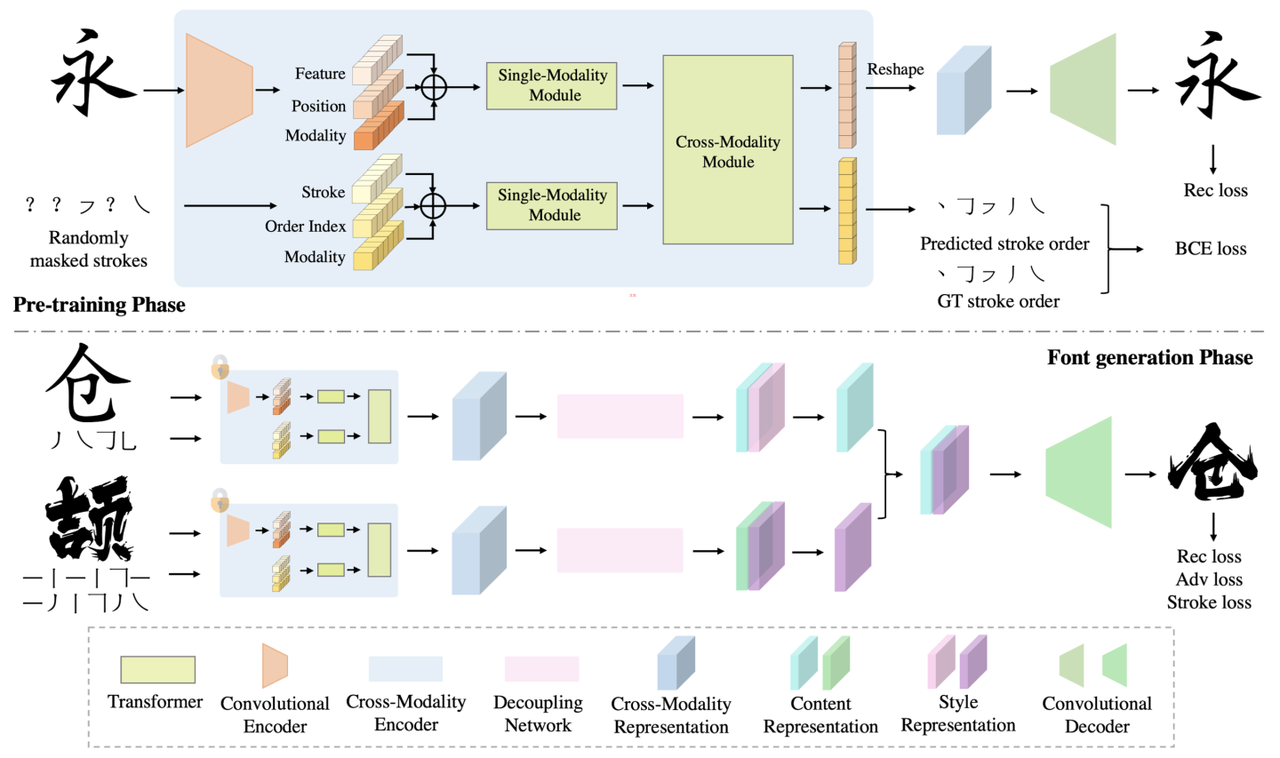
In order to solve this problem, the XMP-Font proposed by the ByteDance intelligent creation team achieved a breakthrough effect and was published in CVPR2022.